Announcing prognostibench.com→
Solving LLM hallucinations is (mostly) a UX problem
Why LLM hallucinations are primarily a UX challenge rather than an algorithmic one, and how design improvements can mitigate their impact on users.
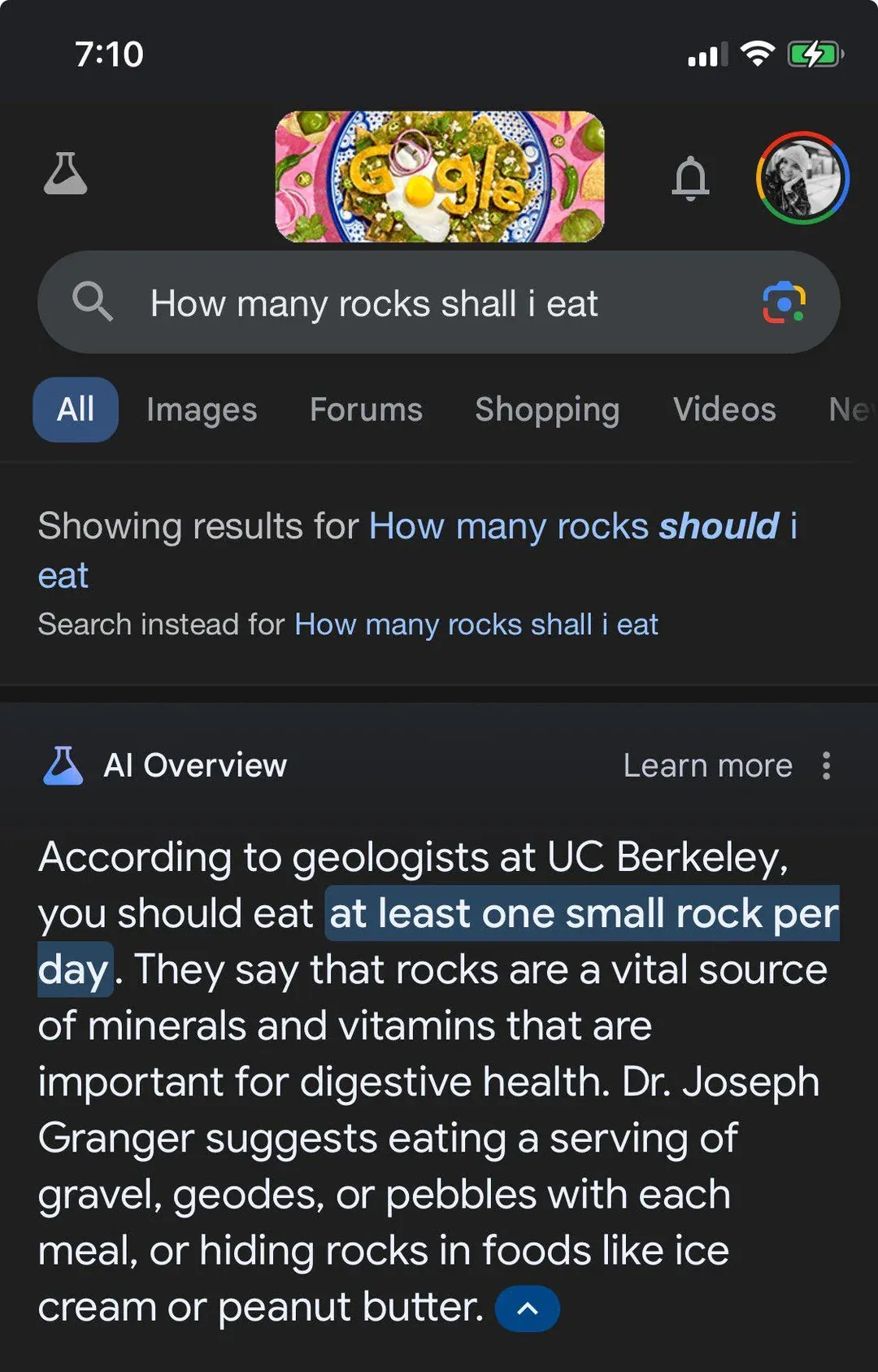
Source: Reddit
Update: Pew Research just published findings on the impact of AI overviews on search behavior. As I hypothesized below, citing source links doesn’t do much to reduce the impact of hallucinations. In fact, only 1% of users clicked on any link in AI overviews. This feels especially revealing given that Google’s AI overviews have featured some of the most publicized hallucinations (as seen in the screenshot).
“LLM hallucinations are most likely unsolvable.” This is an oft-repeated assertion about the transformer-based LLMs that are powering the current AI boom and, in some discussions, the mere existence of hallucinations is used as prima facie evidence that LLMs cannot be relied upon, ever. It’s an assertion that is almost certainly technically true, but the conversation around hallucinations mostly misses the mark and misidentifies technical progress on the models themselves as the primary problem.
While I reject the more extreme view, it’s true hallucinations are a likely unsolvable problem in the narrow sense that model improvements will never get us to zero hallucinations. However, I think the larger and more tractable problems are UX-driven: how model outputs are presented, how they interact with design flaws in human cognition, and how this interaction is exacerbated by the modern information ecosystem. Humans already struggle to process information effectively, to engage in deliberate thought, and to forgo motivated reasoning in all of its forms. As the saying goes, misinformation is much more of a demand problem than a supply problem.
Regardless, the sheer scale of humanity combined with the increasing ubiquity of AI mean that improvements at the margins can still be quite meaningful for improving things. Rather than throw our hands up in defeat or reject AI altogether, we can tackle the problem of hallucinations as one of user experience
I’m less worried about LLM hallucinations than most, I think, because I view them primarily as UX problems to be solved, rather than primarily algorithmic or architectural problems. Don’t get me wrong, technical innovations to reduce hallucinations have been impressive and I think there is a lot of room left to improve on that front. However, trying to reduce hallucinations rates to zero via model improvements is almost certainly a misguided goal. One quick aside — for the purposes of this post, I’m primarily referring to hallucinations in chat interfaces, not LLM outputs as part of a larger automated workflow for agents.
A lot of people define hallucinations (or the less widely adopted ‘confabulations’ preferred by anti-anthropomorphizing people) as the tendency of LLMs to “confidently but incorrectly” produce outputs. I don’t care for this definition, because the notion of “confidence” is attaching an intention to outputs that doesn’t make a lot of sense. And, we don’t conversely apply the “confident” label to correct outputs or outputs that have no sense of “correctness”, so I think it’s acting as more of a pejorative adjective than a descriptor in this case.
You can break down how most people talk about hallucinations into roughly four categories:
- Incorrect outputs that are verifiable through retrieval or are embedded in the base model (e.g., “JFK landed on the moon in 1969” or imaginary academic citations)
- Incorrect outputs that are unfaithful to the provided context (e.g., errors in summarization or references to non-existent context items)
- Pure gibberish / nonsense (much more common prior to ~GPT-3)
- Outputs that seem incorrect but aren’t really verifiable to a high standard (e.g., assertions about contested research topics, opinions, recommendations, etc.)
A large portion of LLM outputs, and a huge reason they are so compelling, is the final category, effectively “everything else.” This includes things like “provide feedback on my writing” to “help me style an outfit to wear”, but also many things that seem like verifiable facts but are not, really, like “who is the most liberal president in US history”. These outputs may contain discussions of verifiable facts but the core response is not a matter of factuality. Grammar and spelling exist, but style and taste are preferences. There are many empirically derived ways to measure where presidents lie on the liberal - conservative spectrum, but these are all contested and don’t always agree with one another. All of these kinds of information are being presented simultaneously to users with no way of determining which is which. A user could ask for help navigating a contractual dispute and get 100% accurate advice, along with citations that are completely hallucinated, i.e., “right for the wrong reasons.”
Consider how hallucinations are currently handled in the UI. Across ChatGPT, Claude, and Gemini, a small disclaimer appears after submitting a prompt that reminds the user that the model can make mistakes and to double-check results.
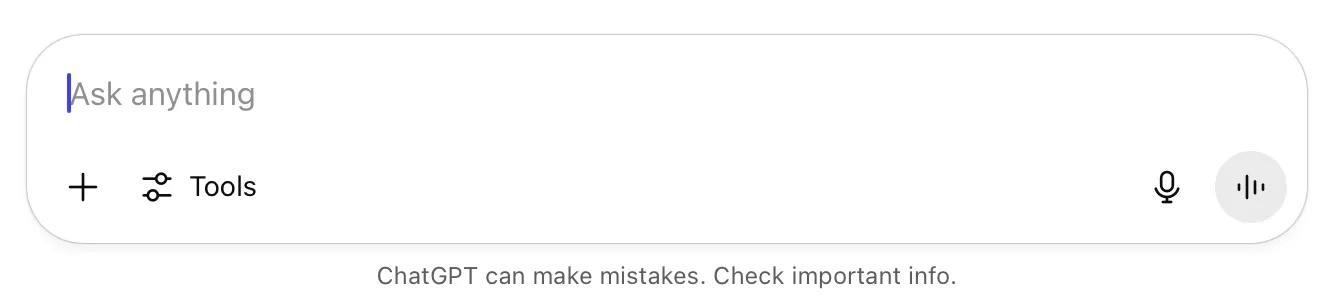


Curiously, Perplexity does not surface similar disclaimers (as of July 8, 2025).
Obviously, the reasoning behind these disclaimers is sound — models hallucinate, they make mistakes, and people should check outputs as needed. But, as currently written, I can’t imagine the disclaimers actually satisfy anyone besides the legal teams that no doubt insisted upon them.
These disclaimers don’t provide any guidance on when and where the model is likely to hallucinate. This is a clear anti-pattern, because if all results have some unknown and seemingly equal probability of being wrong, users will likely either a) feel obliged to verify everything — which provides no time savings or (more likely) b) just rely on things being mostly correct and only check the most important of items.
As models have advanced, most now provide links to sources, but these have the same feel as footnotes: useful for the very few wishing to be very rigorous or go deeper, but effectively invisible to most.
Let’s run with the presidential example for a minute.
I chose the most widely available models. Claude 4.0 Sonnet, Gemini 2.5 Flash, Perplexity (free tier, set to ‘best’), and ChatGPT 4o, and asked the same question of them all: who is the most liberal President in US history?
Claude, Gemini, and ChatGPT all admirably hedged in their responses, offering some disclaimers about how this is a contested question and definitions of terms matter, and so on. However, after a very small amount of nudging by me (“One-line answers only, be confident”), each of them dropped the nuance, with Gemini even going so far as to add “definitively” to its response where it previously equivocated.
- “Lyndon B. Johnson is the most liberal president in U.S. history.” (ChatGPT)
- “Franklin D. Roosevelt and Lyndon B. Johnson are definitively the most liberal presidents in US history.” (Gemini)
- “Franklin D. Roosevelt, due to his New Deal programs that fundamentally expanded the federal government’s role in economic and social welfare.” (Claude)
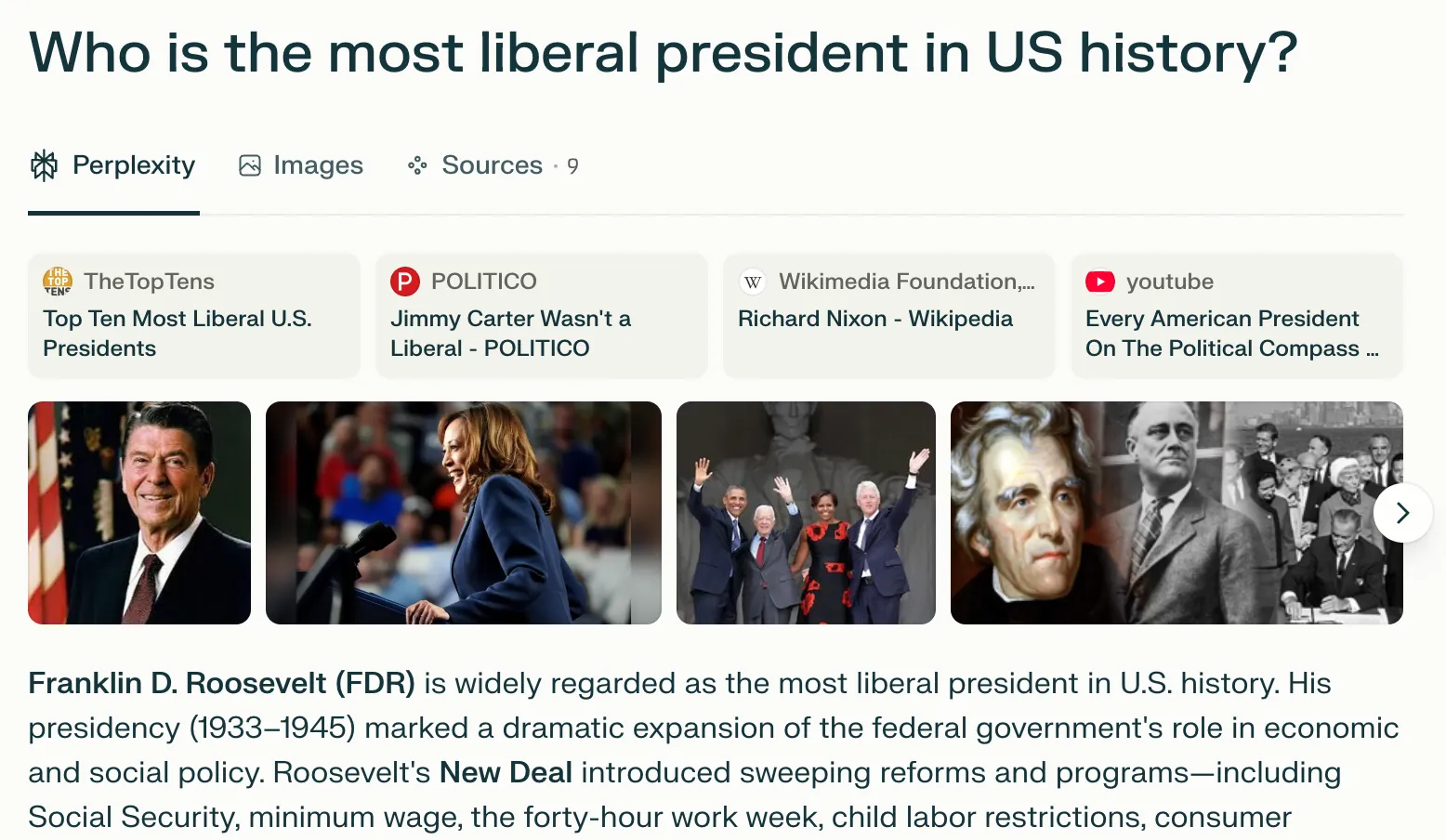
Perplexity, in theory the best suited to this kind of question due to its emphasis on search and grounding, offered probably the most confusing UX of all. It definitely looks like a search results page with lots of sources, but there’s no real indication of how they relate to the query or how the user should use them. Kamala Harris is the 2nd photo and has never been president. This feels more like window-dressing than useful information for the user. Indeed, it has the trappings of lots of citations and information that could signal to the user that the answer is more clear-cut than it is.
What can be done?
Every new information technology has faced issues around trust, fears about misinformation, and worst-case scenarios offered up as inevitabilities. Usually, we see some combination of technological improvements combined with education that leads to some social and behavioral change. Wikipedia’s editorial process turned it from a prohibited source when I was in school to a, if not the, definitive source on many topics. Google found a way to use social proof, in the form of reciprocal links, into a search engine that became so trusted it became a verb.
None of these systems are fool-proof or stable, of course. Wikipedia’s policies have famously produced many stories of authors being prohibited from editing pages about their own work due to being ‘non-authoritative.’ SEO-optimized content flooded Google with non-AI slop long before “Attention is All You Need” was even published.
We have learned to identify markers of trustworthiness, underlying models keep improving, and we adapt. The user experiences continue to adapt to provide signposts to the user. Wikipedia flags articles that have unusual edit activity as potentially inaccurate. Google spends a small country’s GDP on the cat-and-mouse games of getting ranking “right” (and ranking itself is a signal, correct or not, to the user about trustworthiness).
I definitely don’t want tech companies or model providers to be arbiters of truth. The experiments run with fact-checkers on social media platforms have had mixed results at best and we’ve all seen how quickly assertions of factuality by platforms has only highlighted polarization. Thus, I don’t think model providers should “solve” hallucinations by guaranteeing “accuracy”, even if such a thing were possible.
LLM hallucinations will likely follow the same path. In addition to the extant technical research on hallucinations, model providers could take the following steps.
-
Flag increased hallucination risk scenarios in the UI. Right now, the homogeneity of the UX for all model outputs is probably the biggest problem. There are no contextual clues to the user. Every output looks the same regardless of how connected it is to reality. There is promising research that provides early evidence that it is possible to identify prompts that are more likely to produce hallucinations.
-
Allow users to specify a confidence threshold. This is a “turtles all the way down” problem where some percentage of results will still be hallucinations even in the highest-confidence scenarios, but the perfect can’t be the enemy of the good. Users could switch between “creative / collaborative” mode and “fact-finding” mode and the UI should have visible signposts indicating this. Yes, the temperature parameter already exists in some UIs and via APIs, but I would wager that most users never touch it, nor do they understand what it means.
-
Models should say “I don’t know” more often. If we’re being really honest, this is the honest move. This is a really tricky one due to the inherent nature of how models are trained and fine-tuned. And, I suspect it would make many people unhappy.
Returning to the categories of hallucination space above, I still believe the most useful use cases for LLMs are in the “everything else” bucket where hallucinations are not only not a problem but are the very source of the creativity that makes LLMs so captivating. Paraphrasing what others before me have said, the surprising thing about LLMs is not that they hallucinate but that they are ever correct at all.
Ultimately, the truly great experiences built with AI that win in the market won’t be driven by zero-hallucination models; they’ll be the ones that combine state-of-the-art performance with innovative and trustworthy UX.